Linux 0.11 源码阅读笔记-文件系统
总览
推荐阅读 我是一块硬盘-码农翻身-刘欣
通俗易懂的介绍了硬盘及文件系统的管理方式, 也简单提了一下inode. 可以作为此部分的入门.
文件系统
本人手工制作的 Linux 0.11 文件系统图解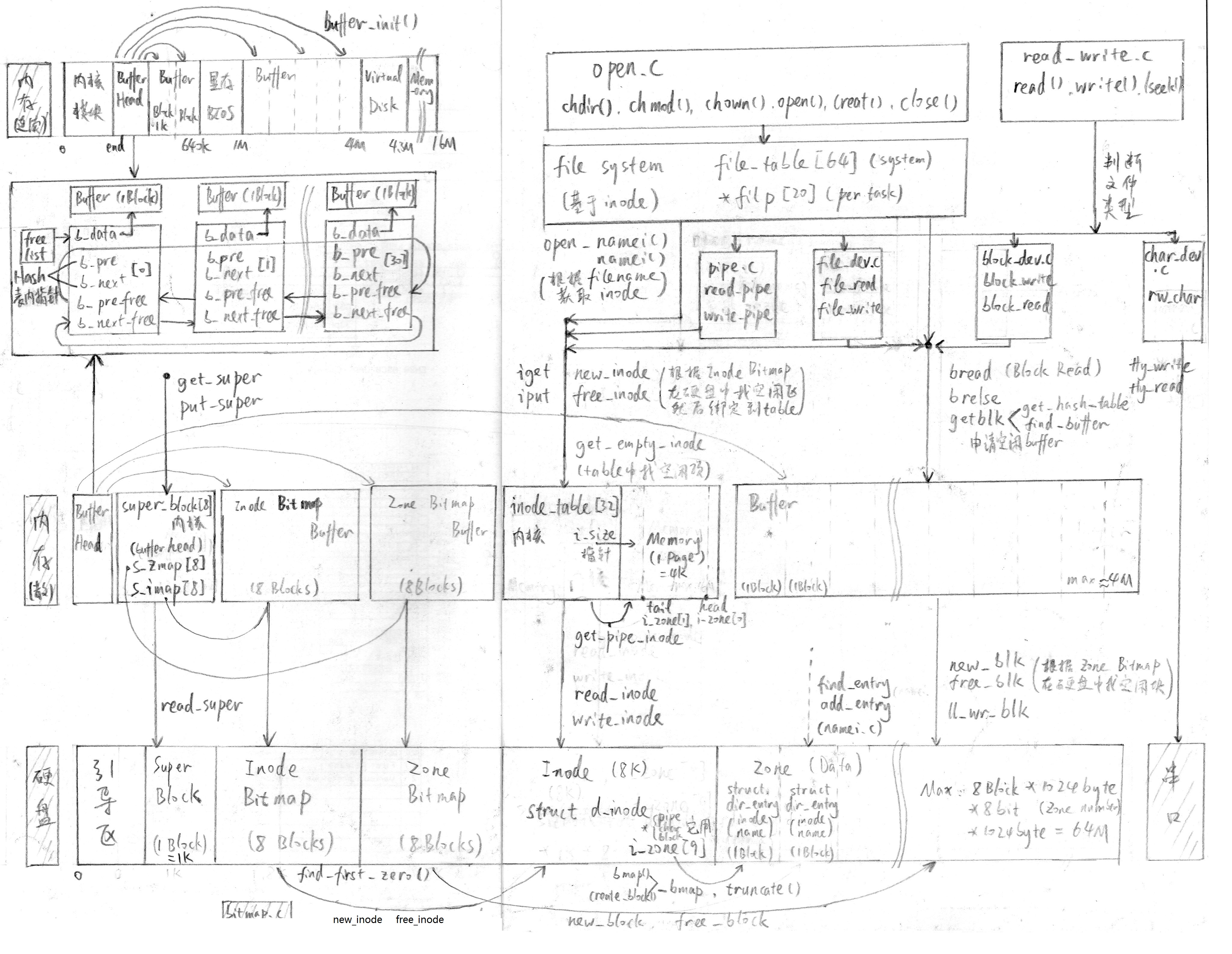
几个核心点:
- Linux下一切皆文件, 文件即i节点!
- 文件名和i节点的关联, 在目录项结构中实现.
索引过程为: 目录inode->目录名/文件名->对应inode->具体内容 - 任何读写硬盘的过程都是通过内存的buffer(高速缓冲)实现的, 系统不能直接读写硬盘! 由此产生同步问题.
调用过程为: 系统函数->buffer->硬盘 - Linux对内存条的分配和使用.
BufferMemory的概念和用途.Buffer HeadBuffer Hash List.Buffer介于高速的CPU指令和低速的硬盘之间, 用于缓存CPU对硬盘的读写内容, 提高CPU执行效率.Memory是系统可用的内存. 系统变量,malloc都是用的这块空间.虚拟内存把使用频率低的Memory暂时搬到硬盘, 以便存放使用频率更高的内存数据. 依赖于硬盘读写操作!
硬盘设备分区
硬盘设备上的分区和文件系统
- 主引导扇区: 存放硬盘引导程序和分区表信息.
- 分区表: 标明了每个分区的类型, 起止位置以及占用的扇区数.
- 相关文件:
kernel/blk_drv/hd.c
下面, 将以MINIX1.0为例说明文件系统的基本概念.
Linux使用的其它的文件系统核心概念都是一样的! 只是支持的大小, 寻址速度, 文件上限有区别.
MINIX1.0 文件系统
MINIX1.0 文件系统布局示意图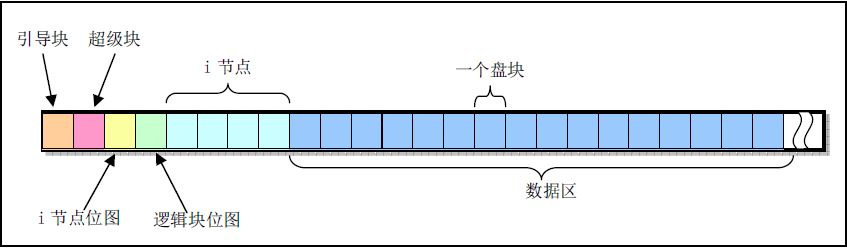
- 引导块: 上电时, BISO自动读入的部分. 有了引导块内引导程序, BIOS才能启动系统
- Super Block(超级块): 存放文件系统的结构信息, 说明各部分的大小.
super_block[8], 可加载8个文件系统 - Inode Bitmap(i节点位图): 记录i节点的使用情况, 1bit代表一个i节点.
s_imap[8], 占用8个块, 可表示8191个i节点情况 - Zone Bitmap(逻辑块位图): 记录数据区的使用情况, 1bit代表一个盘块(block).
s_zmap[8], 占用8个块, 最大支持64M的硬盘 - Inode(i节点): 每个文件或目录名唯一对应一个i节点, 在i节点中, 储存 id信息, 文件长度, 时间信息, 实际数据所在位置等等
- Zone Data(数据区):
8 (bit/byte) * 1024 (byte/block) * 8(zmap blocks) * 1024 (byte/block)= 64M byte
MINIX1.0 的超级块数据结构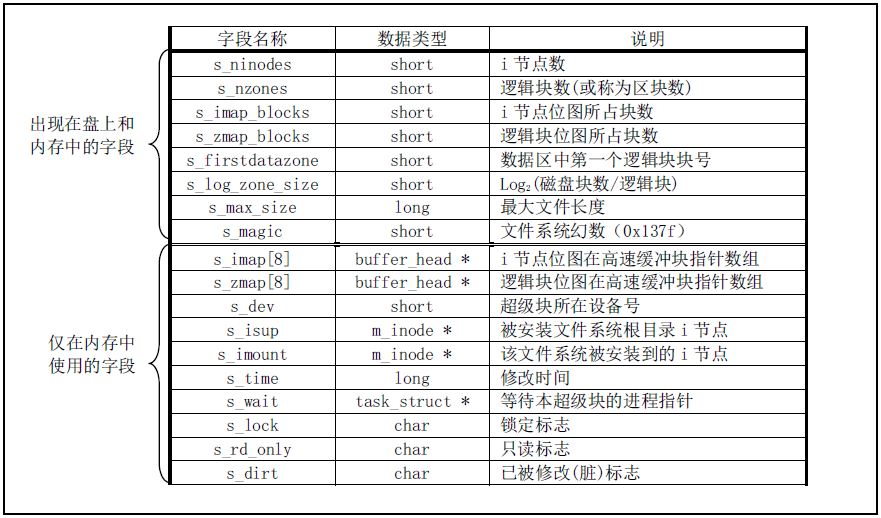
一切皆文件
inode 详解
MINIX1.0 的i节点数据结构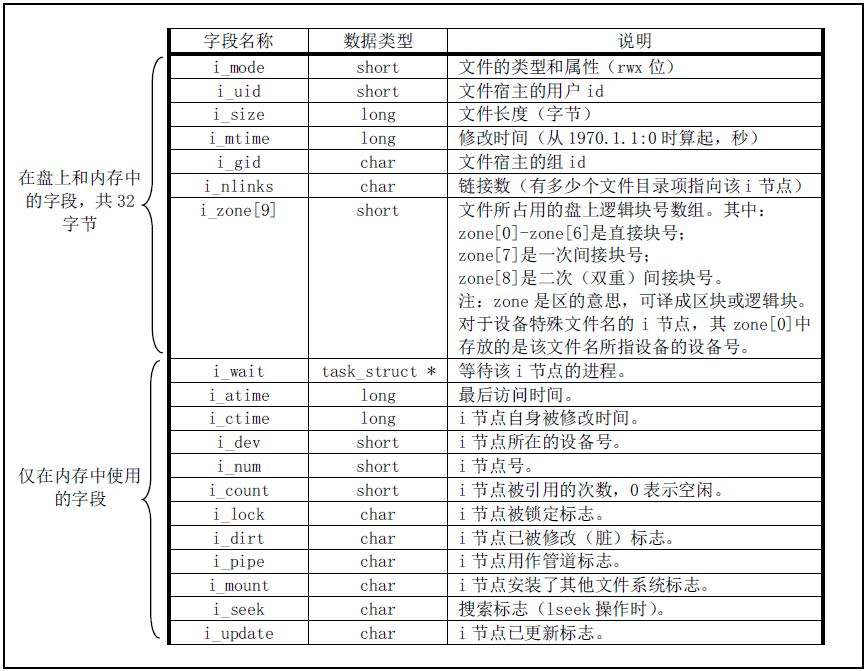
i_nlinks: 硬链接计数器. 因此硬连接具有相同的inode号, 硬连接不能跨文件系统!
命令 ls -l 显示的文件信息, 多数信息读取i节点就可获得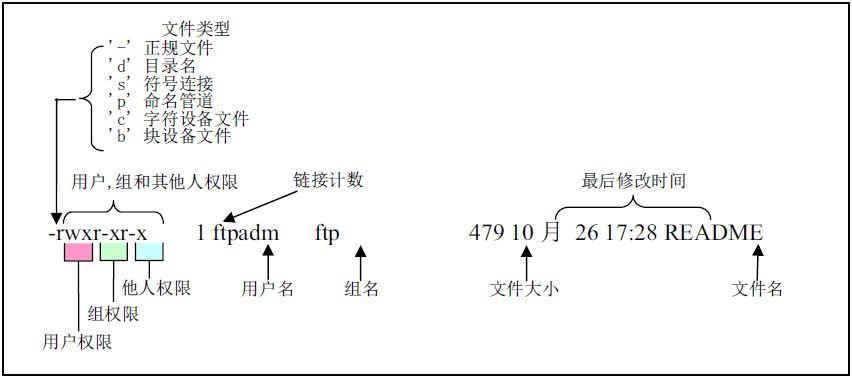
- 符号连接
s: 就是常说的软连接, 类似于windows下的快捷方式, 占用i节点, 在对应的数据块内存放路径
i_zone[9] i节点的逻辑块数组功能.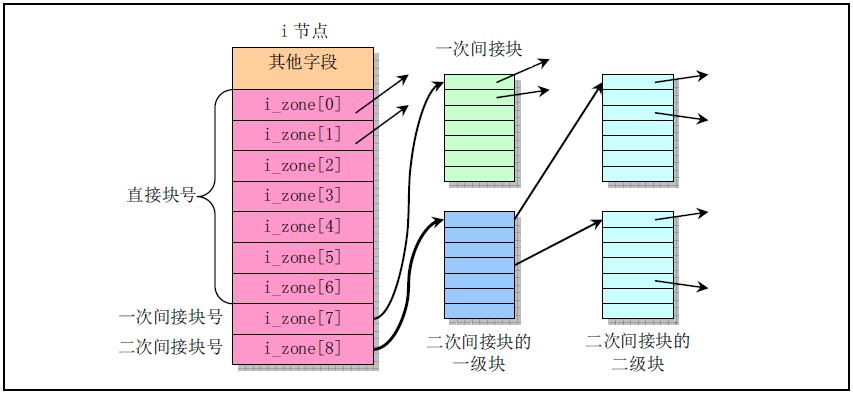
i_zone[0-6]直接块号: 存放文件开始的7个磁盘块号. 此时文件大小:7*1024(byte/block)=7K bytei_zone[7]一次间接块号: 地址占用2byte, 因此一个数据块可存放512个地址. 此时可寻块7+512 blocksi_zone[8]二次间接块号: 此时可寻块7+512+512*512 blocks, 文件的最大可达512M byte/dev/下设备文件的i_zone[0]: 设备文件不占用硬盘, 因此i节点仅保存设备的属性和设备号.
文件名的存储及查找
Linux 0.11 的目录项结构
// 定义在 include/linux/fs.h 文件中 |
- 可见, linux下的文件名称都存在了目录项的数据里面, 并且唯一关联其i节点号.
- 每个目录项占用16字节, 因此, 一个盘块可以存放
1024/16=64个目录项 - 对于空目录, 也至少会有名称未
.和..两项, 指向当前目录inode和上级目录inode - 因此, 空目录的硬连接计数值
i_nlinks为2, 每多一个文件,i_nlinks再加1.
通过文件名最终找到对应文件盘块位置的示意图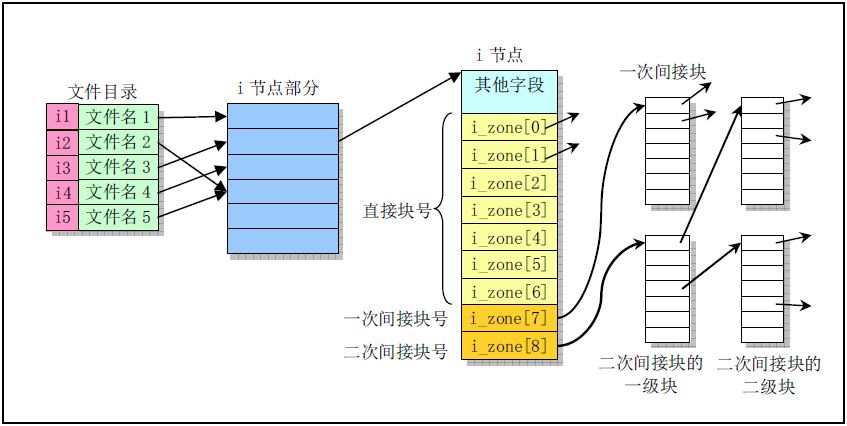
整个搜索过程是根据目录项结构及对应的inode 号, 逐步深入路径的过程.
以路径名 /usr/bin/vi 搜索对应的i节点, 然后读取文件内容为例:
- 根目录
/具有固定的 inode号1. - 读取
inode 1的数据块, 搜索名为usr的目录项, 从而得到/usr的inode号, 假设为23 - 读取
inode 23的数据块, 搜索名为bin的目录项, 假设/usr/bin的inode号为61 - 读取
inode 61的数据块, 搜索名为vi的文件名, 假设获得/usr/bin/vi的inode号98 - 读取
inode 98的数据块, 根据i节点信息, 如i_sizei_zone[9], 最终读取文件内容
高速缓存 buffer.c
buffer_head 的数据结构
struct buffer_head { |
buffer的初始化
buffer的双向循环链表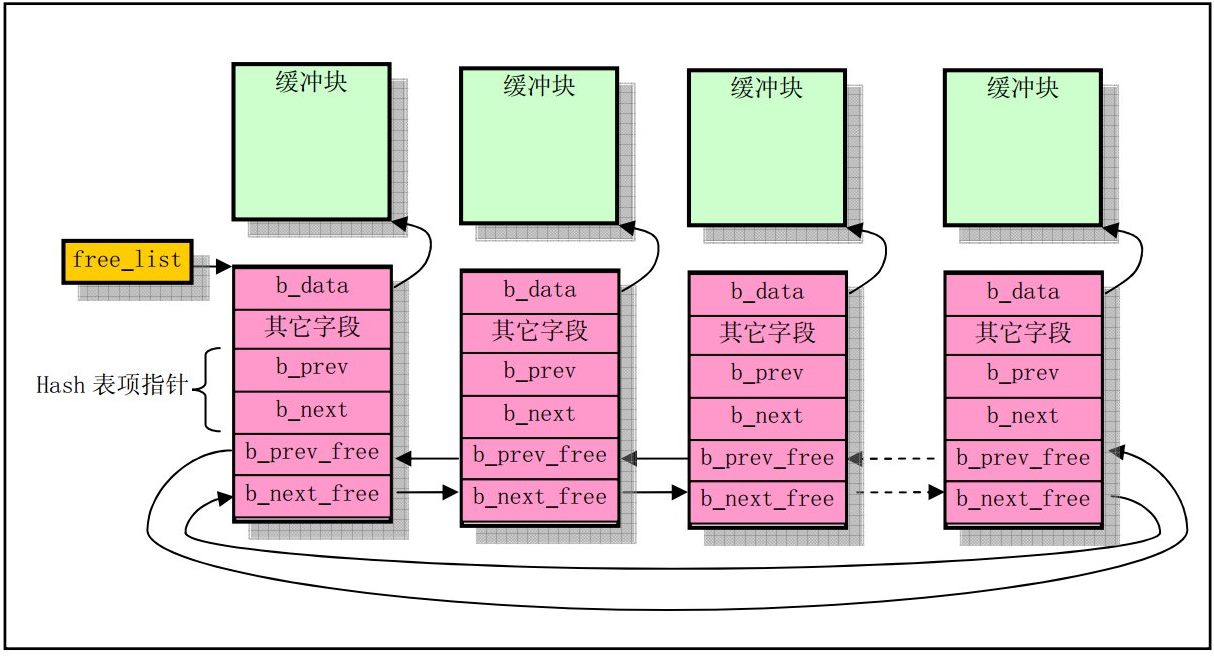
- 该双向链表是最近最少使用LRU链表(Least Recently Used),
free_list指向最为空闲的缓冲块指针
buffer的hash表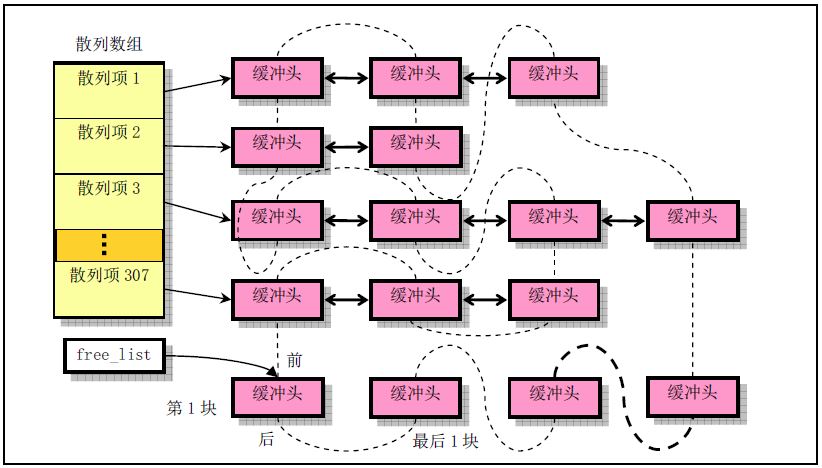
- Linux 0.11 使用的hash函数是
设备号^逻辑块号 Mod 307, 因此共有307项hash表 - hash的功能类似于字典, 先预先归类, 然后可以按类查找, 加快了查找速度.
缓冲区管理函数关系图
详解 getblk() 函数. 用于寻找最为空闲的buffer缓冲块.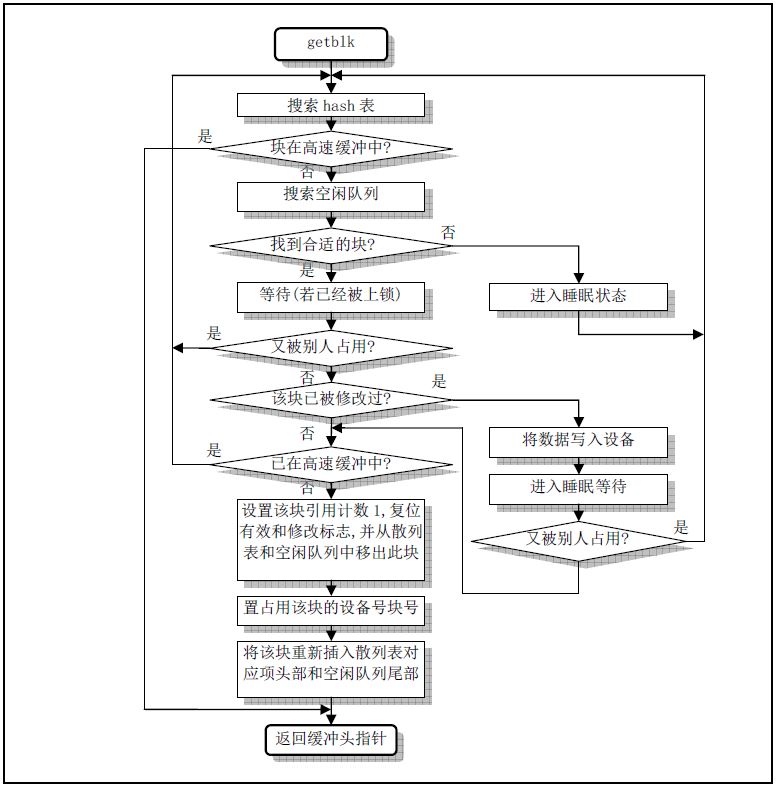
- 首先调用
get_hash_table(), 查看搜索的指定缓冲块是否已经存在于buffer中. 存在就立刻返回该buffer指针. - 不存在时, 从空闲链表头开始扫描, 寻找最合适的空闲块(没有被使用, 没有被上锁, 没有被修改). 实现LRU
- 因为可能别的进程已经加入了所需的缓冲块, 因此再调用一遍
get_hash_table() - 此时, 可以将块应用计数置1, 把该缓冲块移到空闲队列末尾.
参考
原创于 DRA&PHO